When the Gold Standard Isn't Necessarily Standard: Challenges of Evaluating the Translation of User-Generated Content
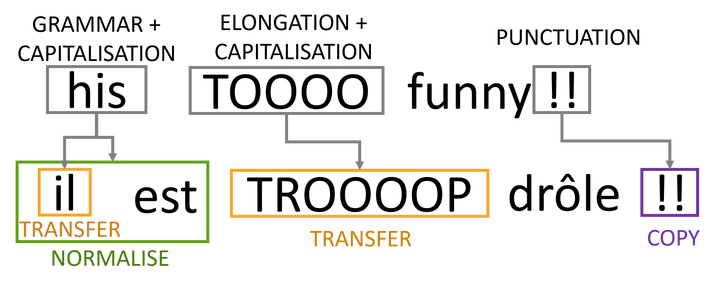 UGC Translation Example
UGC Translation Example
Abstract
User-generated content (UGC) is characterised by frequent use of non-standard language, from spelling errors to expressive choices such as slang, character repetitions, and emojis. This makes evaluating UGC translation challenging: what counts as a ‘good’ translation depends on the desired standardness level of the output. To explore this, we examine the human translation guidelines of four UGC datasets, and derive a taxonomy of twelve non-standard phenomena and five translation actions (NORMALISE, COPY, TRANSFER, OMIT, CENSOR). Our analysis reveals notable differences in how UGC is treated, resulting in a spectrum of standardness in reference translations. We show that translation scores of large language models are highly sensitive to prompts with explicit UGC translation instructions, and that they improve when they align with the dataset guidelines. We argue that fair evaluation requires both models and metrics to be aware of translation guidelines. Finally, we call for clear guidelines during dataset creation and for the development of controllable, guideline-aware evaluation frameworks for UGC translation.
Preprint
Lydia Nishimwe
AI Research Scientist | PhD
AI Research Scientist studying how large models behave, fail, and generalise in the real world.